클로드3·GPT-4의 수학 실력은 "암기 아닌 추론"...'과적합' 벤치마크 발표
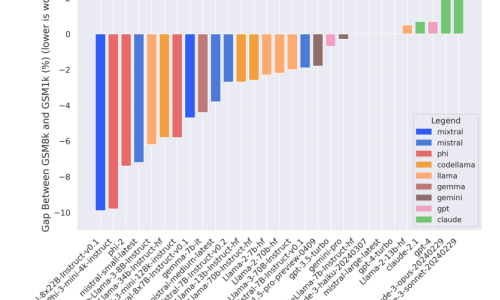
대형언어모델(LLM)의 추론 능력과 암기 능력을 구분하기 위한 새로운 벤치마크 'GSM1k'가 소개되었습니다. 스케일AI 연구진이 개발한 이 벤치마크는 수학적 추론 능력을 평가하여, AI가 실제로 추론하는지 혹은 단순히 데이터를 암기하는지 판단합니다. 기존 벤치마크인 GSM8k와 비교하여, 클로드 3과 GPT-4는 추론 능력이 뛰어난 반면, 미스트랄과 파이 모델은 암기에 의존하는 경향을 보였습니다. 이 연구는 과적합 문제를 해결하고자 하며, LLM의 실제 학습 능력을 더 정확하게 평가하는 데 기여할 것으로 보입니다.
@생각해 볼만한 것@
1. 추론과 암기의 차이: LLM이 제시하는 답변이 실제로는 어떤 과정을 통해 이루어지는지, 단순히 데이터를 암기하는 것인지 아니면 복잡한 추론 과정을 거치는지 생각해 봅시다.
2. 수학적 추론과 인공지능의 발전: 수학 문제 해결은 추론 능력을 판단하는 데 중요한 기준이 됩니다. AI가 인간과 같은 수준의 추론 능력을 갖기 위해 수학적 능력이 왜 필수적일까요?
3. 과적합(Overfitting)은 AI 성능: 과적합이란 AI가 특정 데이터셋에만 너무 최적화되어 다른 상황에서는 제대로 작동하지 않는 현상을 말합니다. AI 학습에서 과적합을 방지하는 방법과 그 중요성 무엇일까요?
4. 벤치마크의 역할은 무엇일까?: 새로운 벤치마크 GSM1k가 도입된 이유와 이전 벤치마크 GSM8k와의 차이점은 무엇일까요? 그리고 이러한 벤치마크가 AI 연구에 어떤 기여를 할까요?
5. 인간의 학습 방식과 모방: AI가 인간처럼 진짜 '배움'을 경험할 수 있을까요?, 그리고 이를 통해 어떻게 인간의 학습과 창의성을 모방할 수 있을까요? AI가 인간의 뇌와 얼마나 유사하게 작동할 수 있는지도 함께 생각해보면 어떨까요?
#인공지능 #인공지능윤리 #인공지능뉴스 #인공지능기사 #AI #AI기사 #인공지능세특 #세특 #입시 #AI세특 #GPT #GPT4 #ChatGPT #인공지능용어 #인공지능지식 #인공지능상식 #AI상식 #AI용어 #AI지식 #LLM #GSM1k #AI추론 #과적합 #AI벤치마크

